
数字人形象声音克隆分身系统
订阅
感谢您选择获客帮数字人视频合成平台。获客帮数字人技术经过数年研发,致力于成为最简单易用的在这里您可以创建自己的AI形象和声音,然后通过打字生成您数字分身的视频。您也可以选择公版形象和声音,通过配置文案生成您想要的视频。
感谢您选择获客帮数字人视频合成平台。获客帮数字人技术经过数年研发,致力于成为最简单易用的在这里您可以创建自己的AI形象和声音,然后通过打字生成您数字分身的视频。您也可以选择公版形象和声音,通过配置文案生成您想要的视频。
1、顶级形象克隆质量:使用1分钟的录像,训练高清嘴型和动作AI模型,创作您的个性化数字分身
2、多语种声音克隆,使用1分钟语音,训练您的专属声音模型,支持说普通话、粤语、台湾腔调、全球主流外语和方言
3、自定义背景:可使用自定义视频或图片背景,干净无瑕疵的人物抠图
4、内置顶级换脸算法:仅需一张照片即可更换视频人物五官
5、智能动作调整:独家AI算法,实现人物动作和说话节奏的精准匹配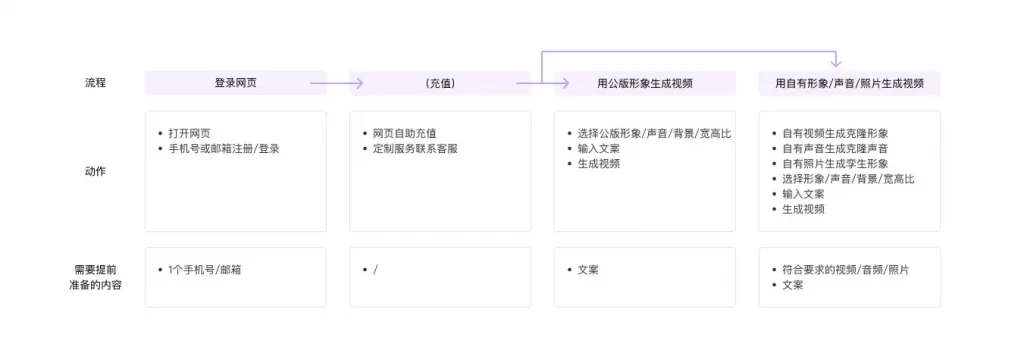
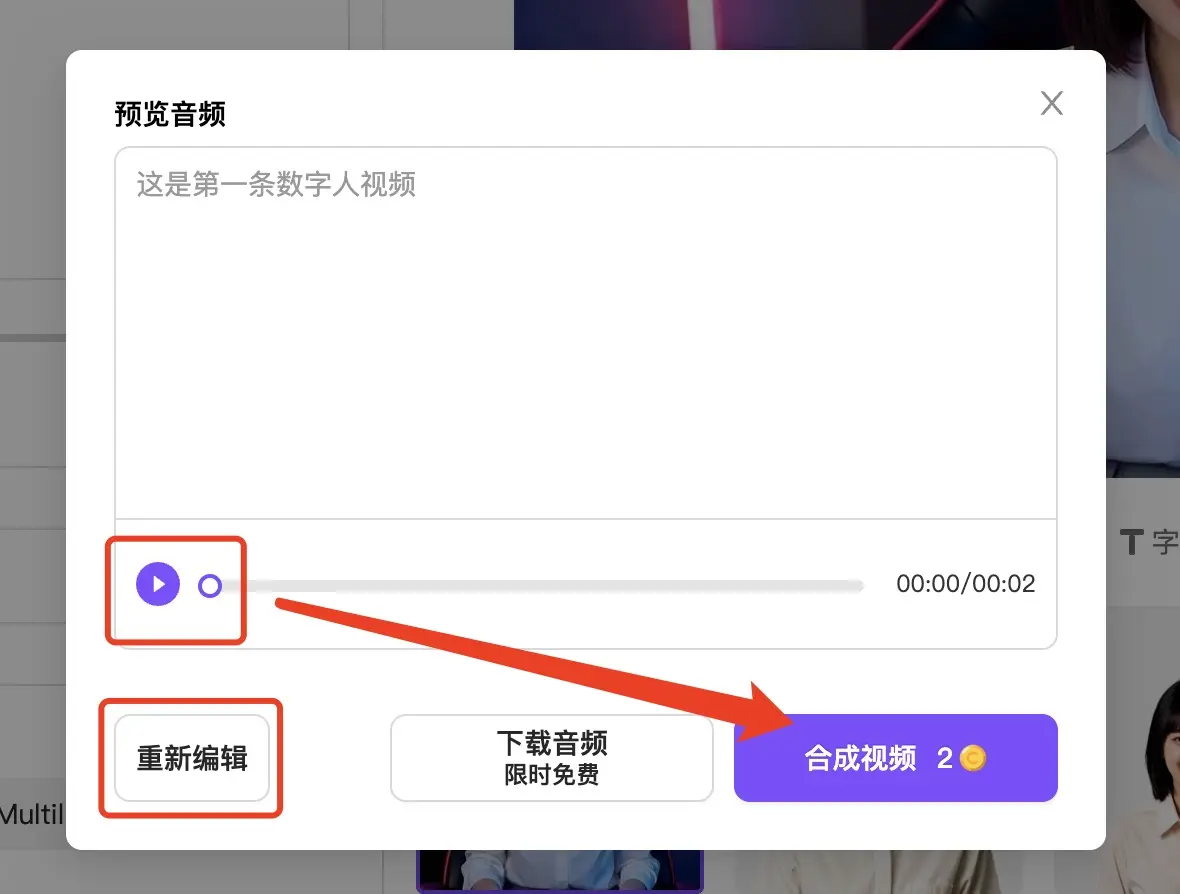 预览音频后,可以看到此音频生成视频需消耗的金币数量。如果音频没有问题,也认可消耗的金币数量,则可以点击“合成视频”来生成视频。点击后,会自动跳转合成结果页面,稍等片刻,您就可以下载数字人视频了。
预览音频后,可以看到此音频生成视频需消耗的金币数量。如果音频没有问题,也认可消耗的金币数量,则可以点击“合成视频”来生成视频。点击后,会自动跳转合成结果页面,稍等片刻,您就可以下载数字人视频了。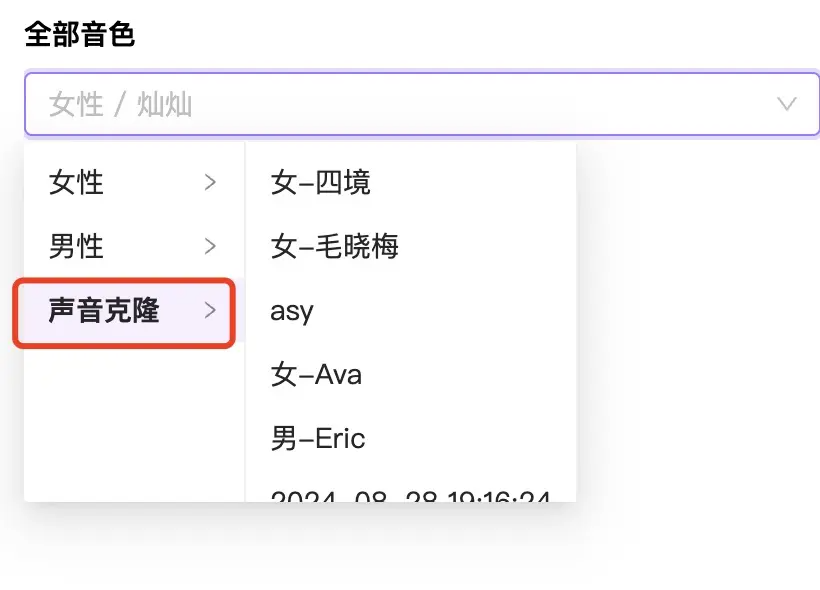
 对于支持更换背景的形象,您可以选择下方提供的公版图片,或上传使用自己的图片/视频作为背景。
对于支持更换背景的形象,您可以选择下方提供的公版图片,或上传使用自己的图片/视频作为背景。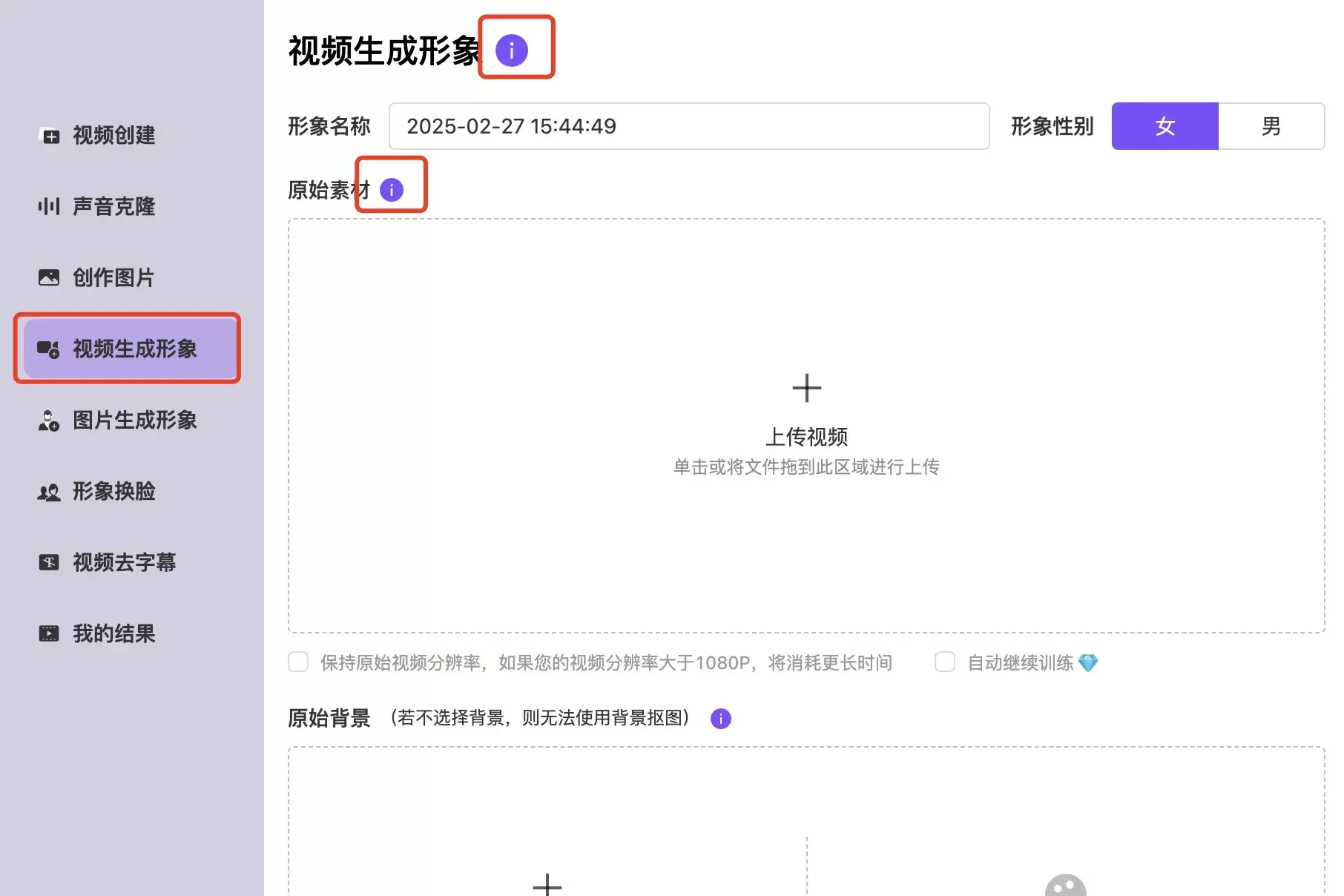
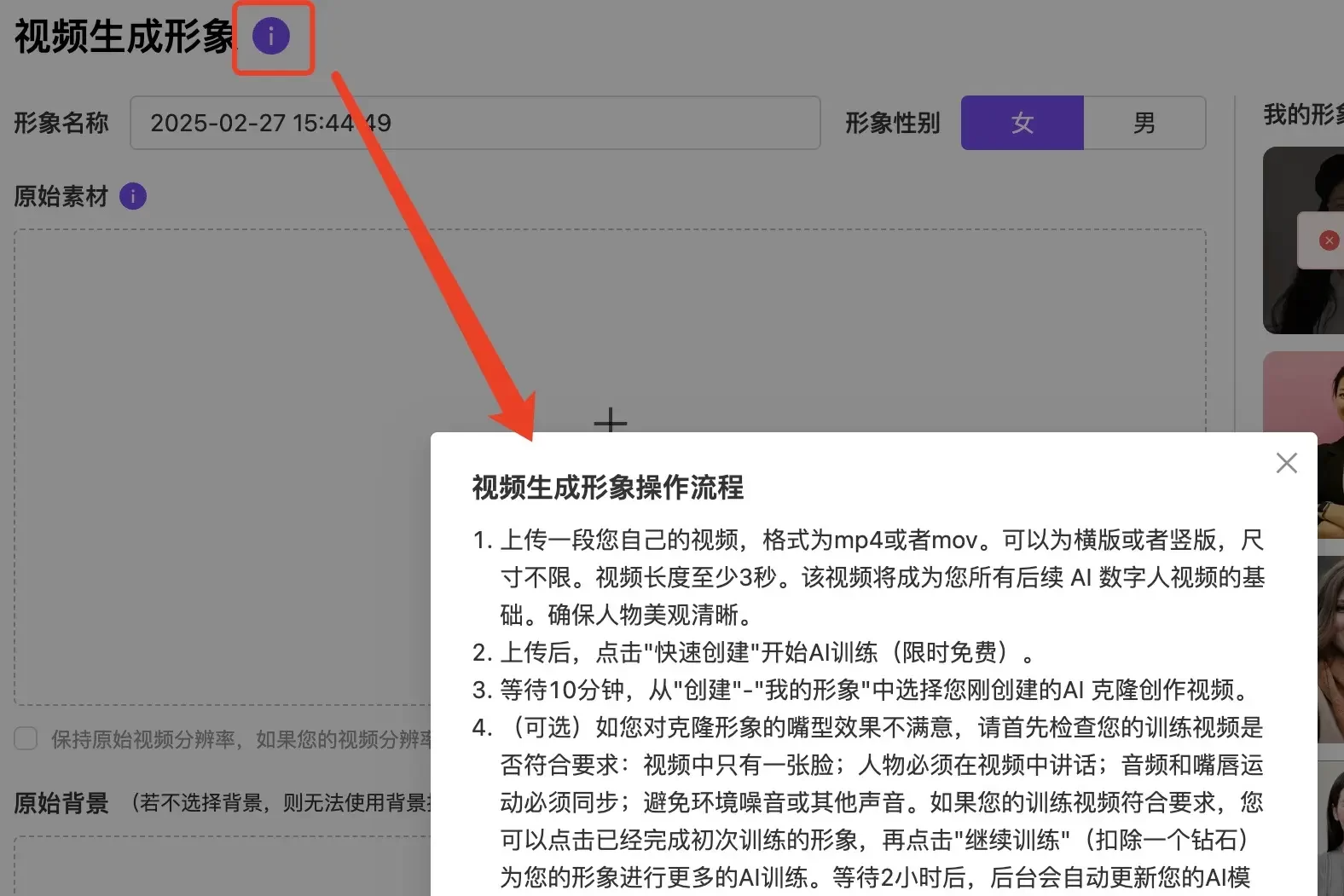 按步骤:1、形象名称:给您的形象输入一个名称
按步骤:1、形象名称:给您的形象输入一个名称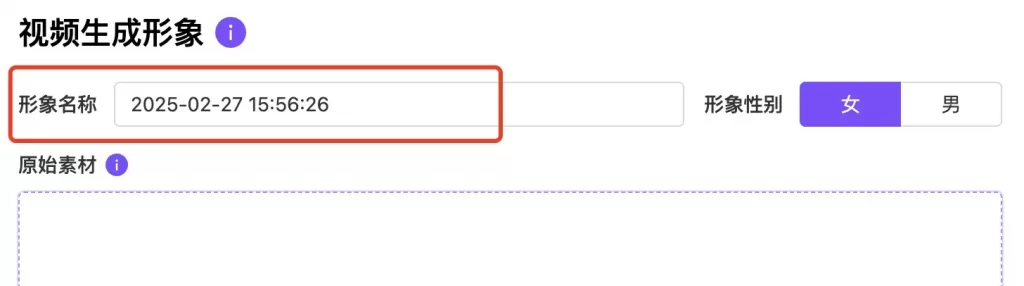 2、形象性别: 根据您基础视频里的人物进行与之对应的性别选择
2、形象性别: 根据您基础视频里的人物进行与之对应的性别选择 3、原始背景:如您希望生成后的克隆形象可以抠图,需要上传原始背景图片
3、原始背景:如您希望生成后的克隆形象可以抠图,需要上传原始背景图片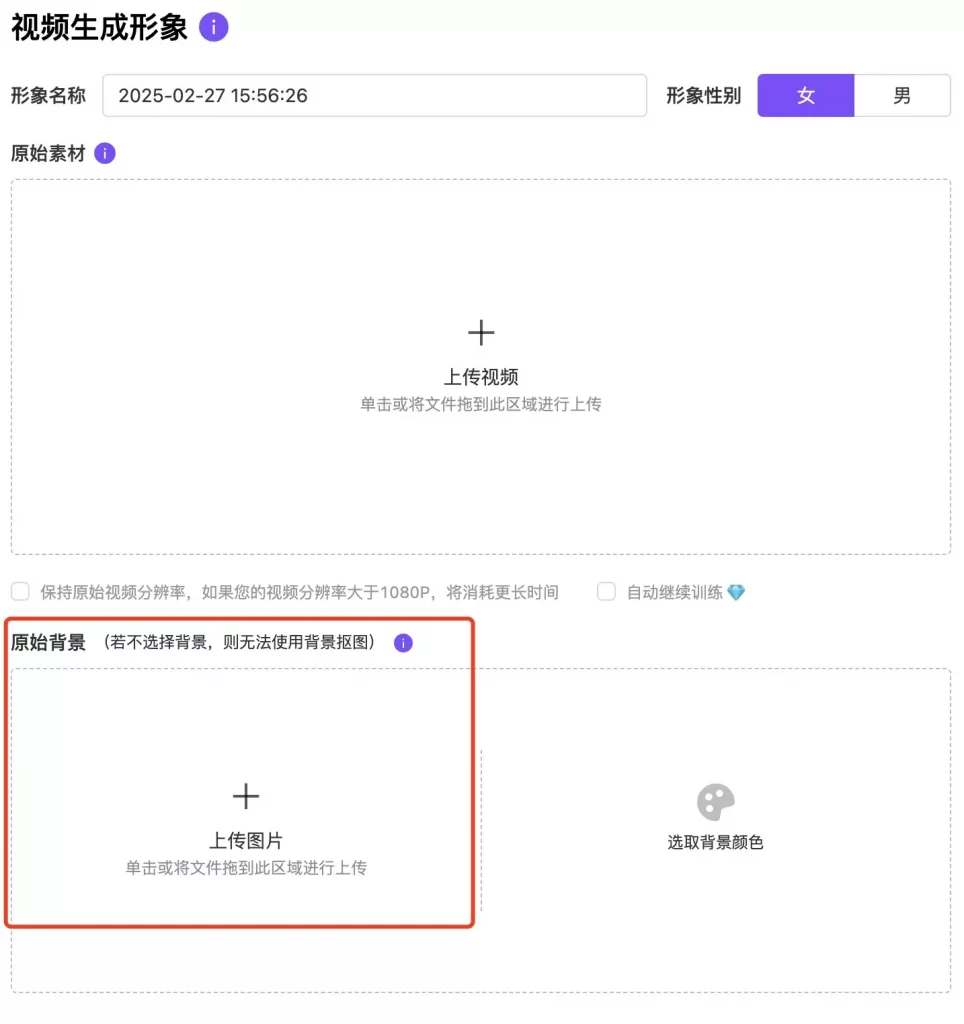 4、如上步骤都操作好后,就可以点击“快速创建”了(瞬时模式),瞬时模式的数字人形象生成成功后,您可以在页面右侧我的形象里查看。回到”创建“模块下找到”我的形象“里面去进行视频生成使用。
4、如上步骤都操作好后,就可以点击“快速创建”了(瞬时模式),瞬时模式的数字人形象生成成功后,您可以在页面右侧我的形象里查看。回到”创建“模块下找到”我的形象“里面去进行视频生成使用。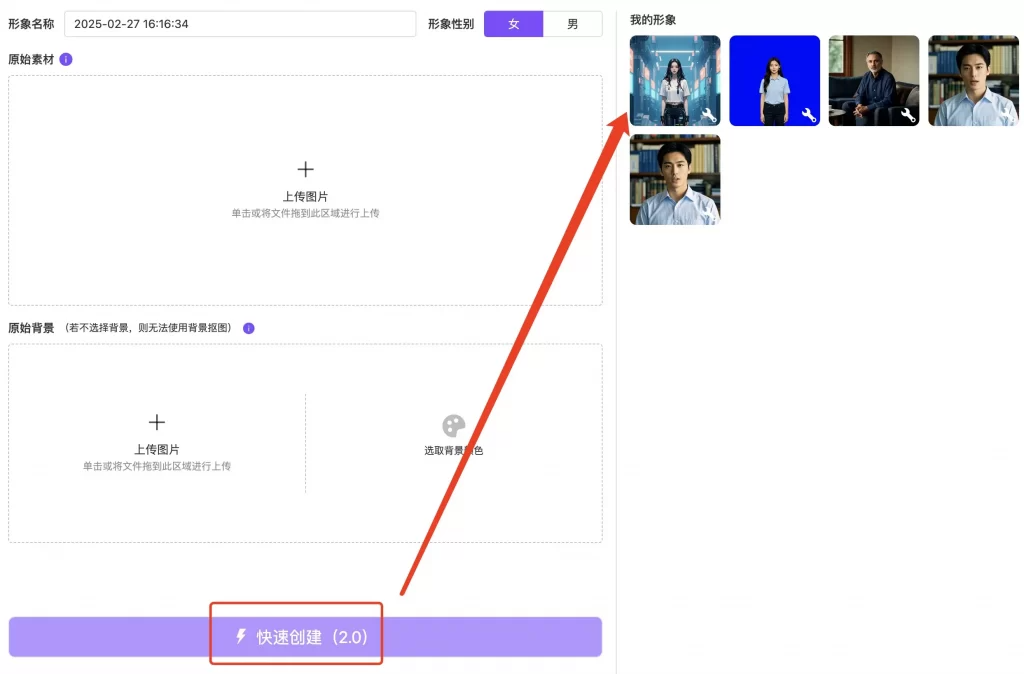 5、如您瞬时模式生成的数字人形象不满意,可在”视频生成形象”模块查看”我的形象”下点击“
5、如您瞬时模式生成的数字人形象不满意,可在”视频生成形象”模块查看”我的形象”下点击“ ”对应的数字人形象消耗钻石选择”专业克隆”
”对应的数字人形象消耗钻石选择”专业克隆” 训练成功后您将得到一个超逼真的数字人模型!某些情况下,在上传基础视频时,会显示“上传文件类型不确定”,解决方法见Q&A3。最终可在“创建”模块,点击“”我的形象”,找到您新生成的基础视频模型。选择您自己的人物模型后,参考“使用公版形象生成视频”的步骤,使用此基础视频模型形象生成短视频。
训练成功后您将得到一个超逼真的数字人模型!某些情况下,在上传基础视频时,会显示“上传文件类型不确定”,解决方法见Q&A3。最终可在“创建”模块,点击“”我的形象”,找到您新生成的基础视频模型。选择您自己的人物模型后,参考“使用公版形象生成视频”的步骤,使用此基础视频模型形象生成短视频。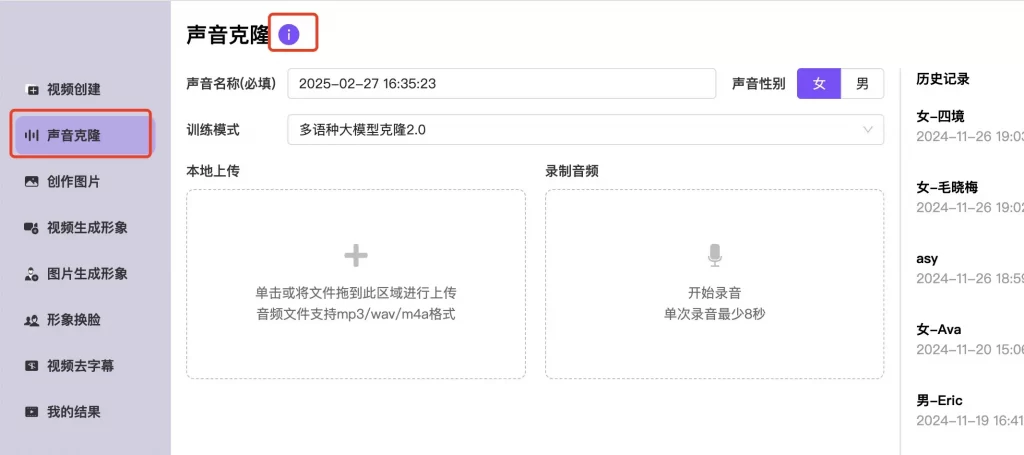
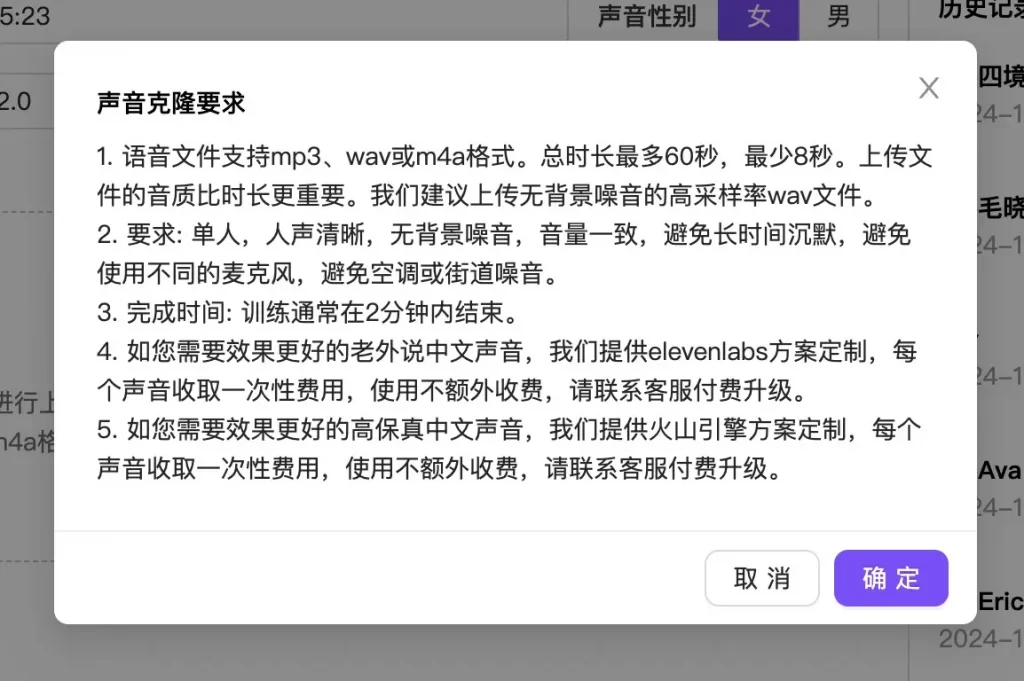 生成的结果可在“创建”模块中使用,在生成短视频选择音色时,在“声音克隆”部分可以看到克隆的音色。目前克隆声音算法还处于持续迭代中。如果您克隆的声音有杂音或者漏字
生成的结果可在“创建”模块中使用,在生成短视频选择音色时,在“声音克隆”部分可以看到克隆的音色。目前克隆声音算法还处于持续迭代中。如果您克隆的声音有杂音或者漏字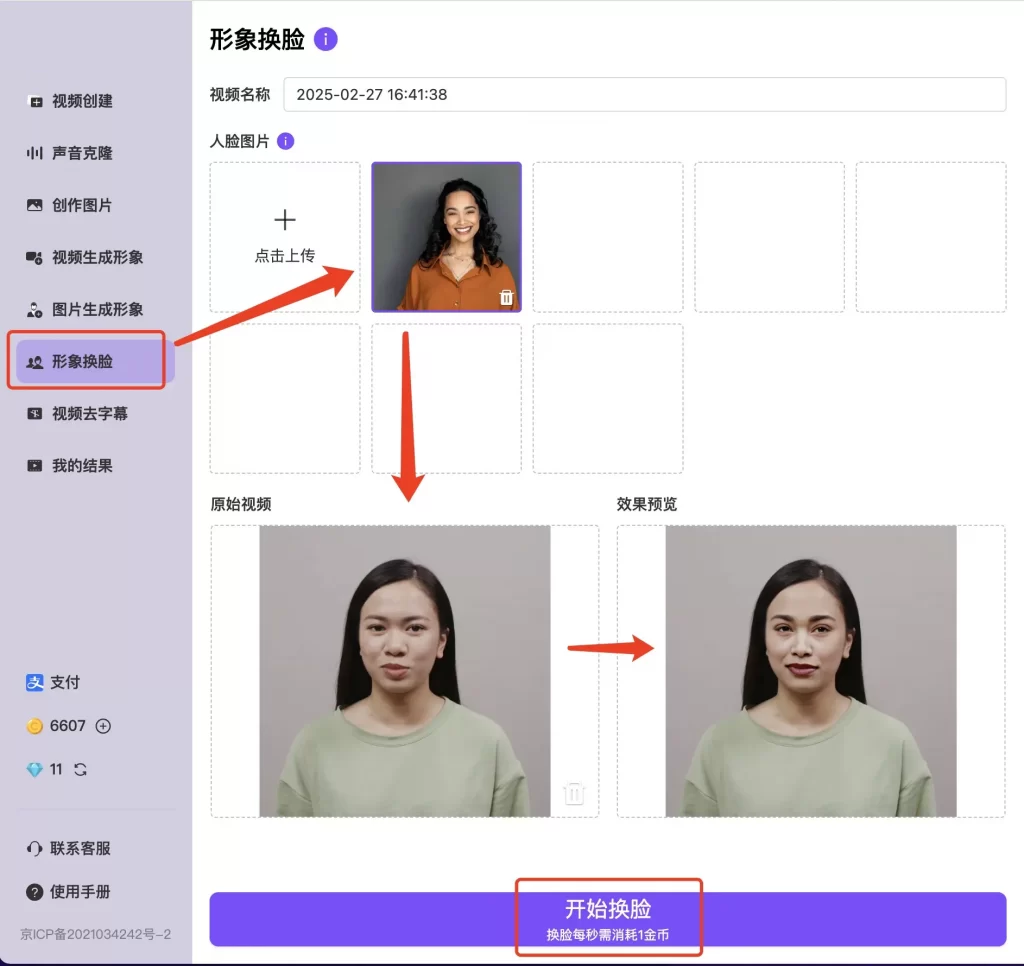
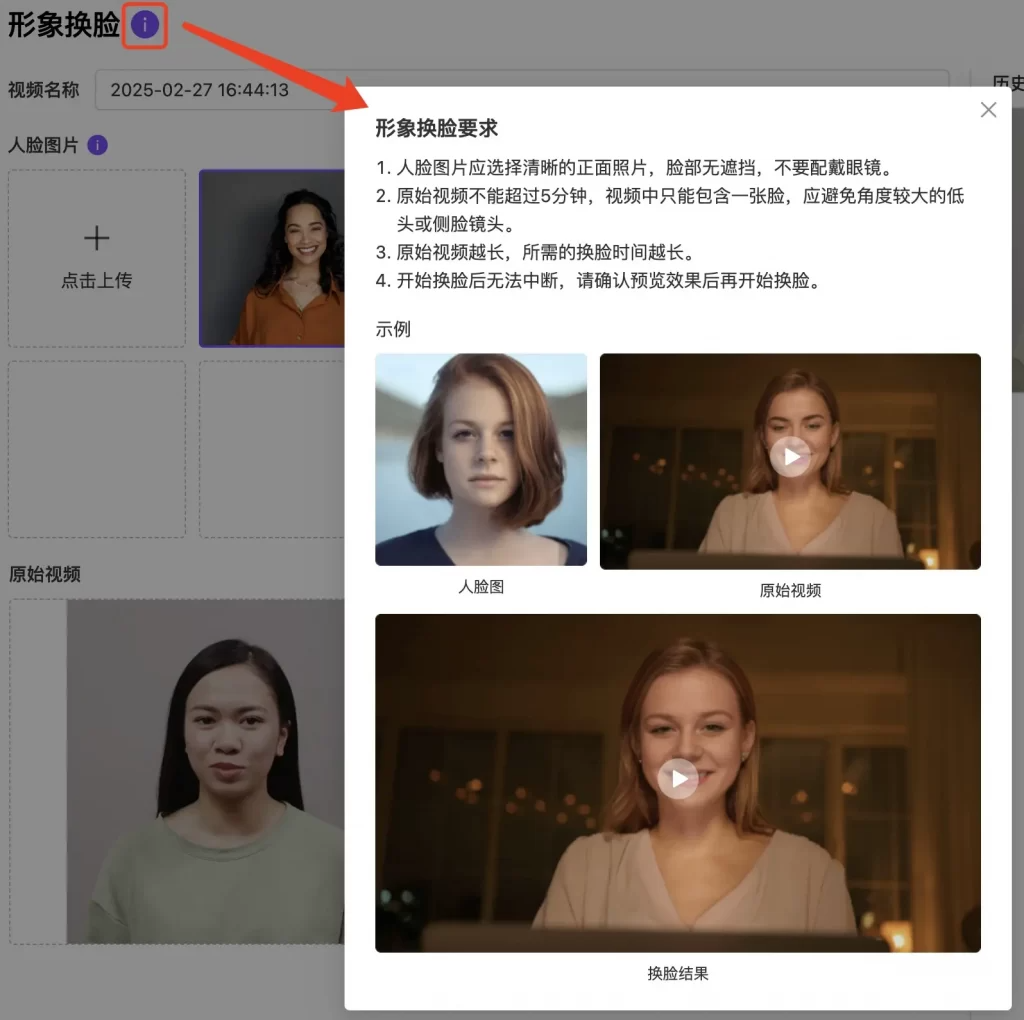 点击开始换脸后,会触发弹窗进行肖像授权,确认后系统进行处理
点击开始换脸后,会触发弹窗进行肖像授权,确认后系统进行处理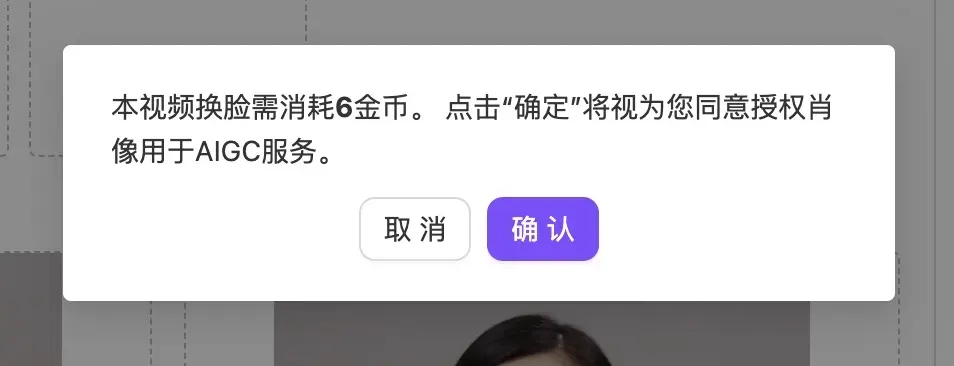 换脸视频生成成功后可以从页面右侧历史记录里查看通过上述操作,可以生成您想要的换脸视频了。
换脸视频生成成功后可以从页面右侧历史记录里查看通过上述操作,可以生成您想要的换脸视频了。
 生成成功后您可以在页面右侧查看结果视频
生成成功后您可以在页面右侧查看结果视频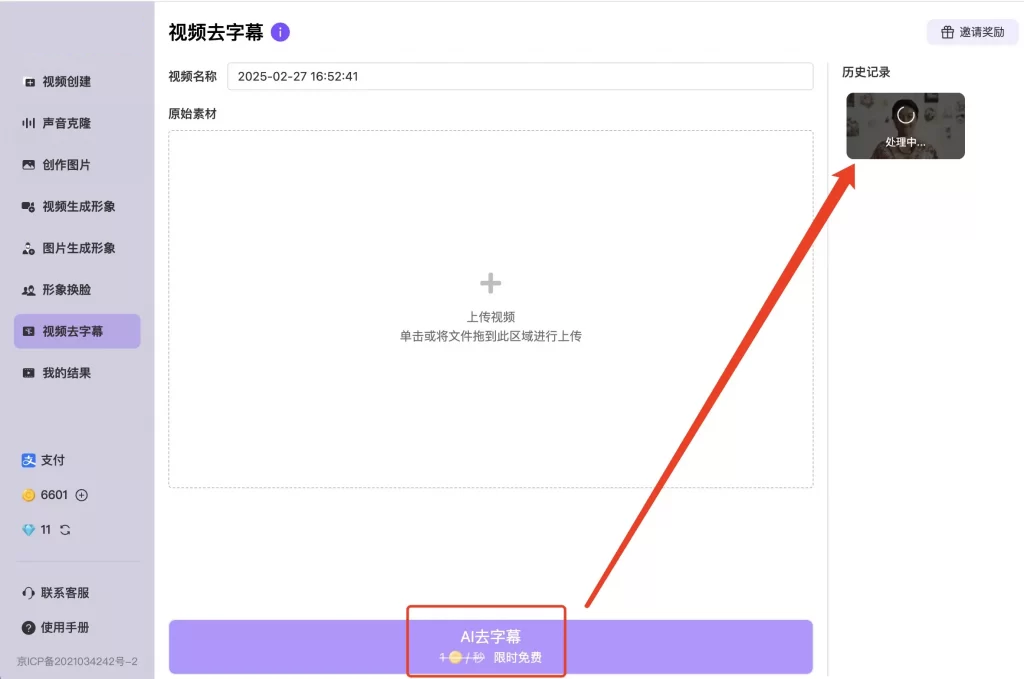
1、顶级形象克隆质量:使用1分钟的录像,训练高清嘴型和动作AI模型,创作您的个性化数字分身
2、多语种声音克隆,使用1分钟语音,训练您的专属声音模型,支持说普通话、粤语、台湾腔调、全球主流外语和方言
3、自定义背景:可使用自定义视频或图片背景,干净无瑕疵的人物抠图
4、内置顶级换脸算法:仅需一张照片即可更换视频人物五官
5、智能动作调整:独家AI算法,实现人物动作和说话节奏的精准匹配
登录
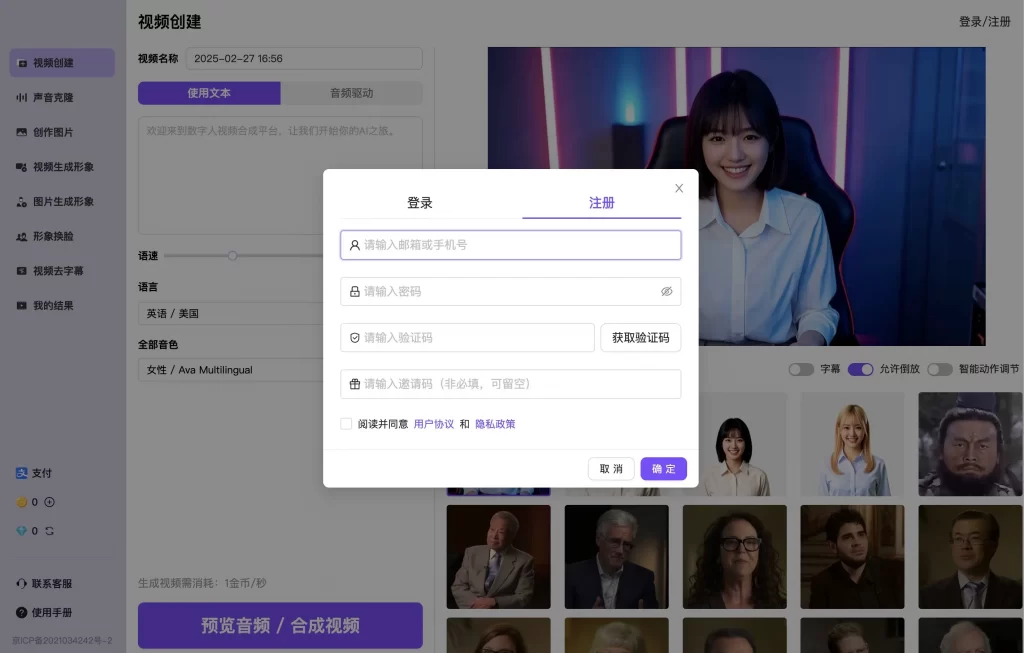
用您注册的手机号/邮箱,登录网址 https://ai.huokebang.cc/ 。 建议您使用电脑端的Microsoft Edge 或Chrome浏览器。使用您的已有账号登录,或点击“注册”注册新账号。详情可以添加微信:daxiong518168创建您的第一条视频
登录后,先试试创建一个数字人视频吧!点击“视频创建”模块,给视频起个名称,然后输入您希望数字人口播的文字,记得选择恰当的语言和音色。点击预览音频。点击预览音频后,会触发弹窗,可以预览音频,或者内容不满意可以重新编辑。合成视频高级功能
选择不同数字人形象
您可以选择自己创建的形象,或者公版数字人形象进行视频合成。公版数字人为平台提供的样例数字人形象,仅做学习参考,平台不保证版权和商用性。选择数字人声音
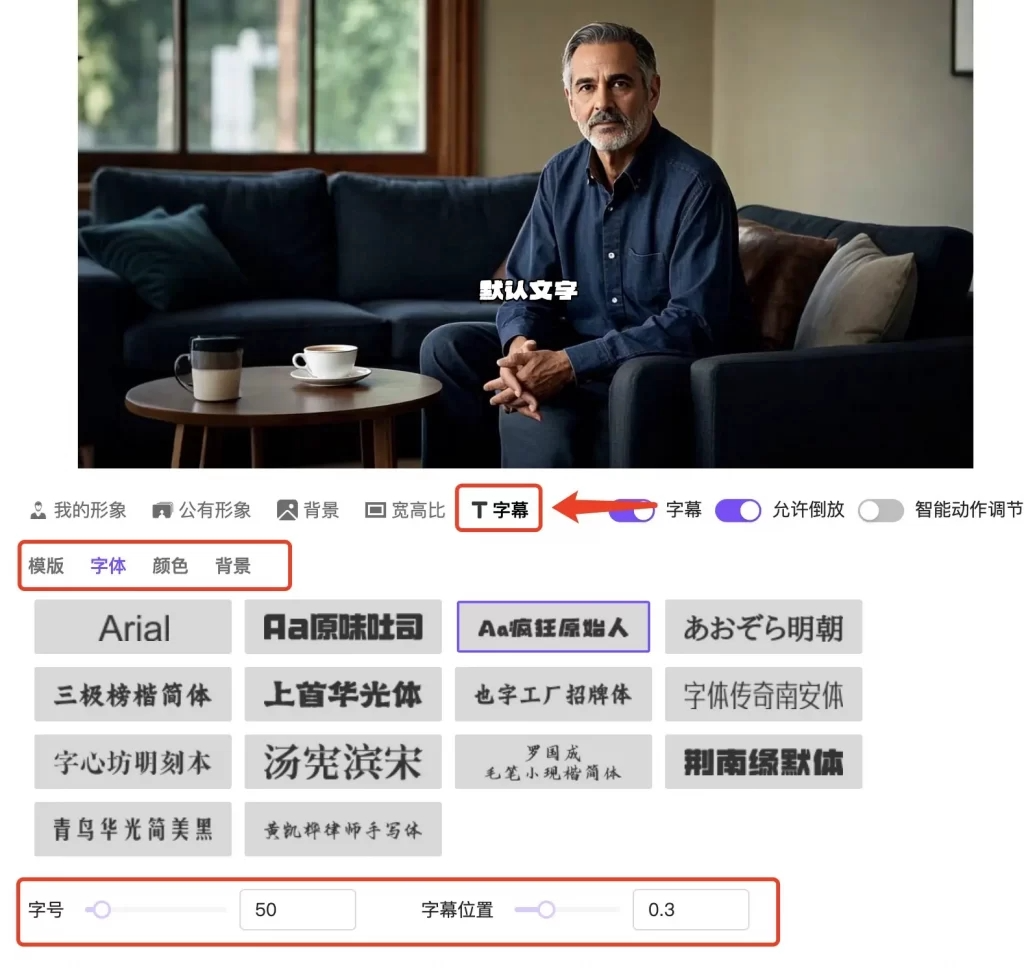
在创建视频的时候,记得选择适合您文案的声音。我们提供数十种语言和上百种音色。您还可以使用自己克隆的语音进行配音。自动创建字幕
首先点选数字人画面下方的“字幕”开关,再点击“字幕”功能配置。就可以对字幕的字体、颜色、背景进行配置。字幕仅支持通过“使用文本”创建的数字人视频,不支持“音频驱动”的数字人视频。更换背景
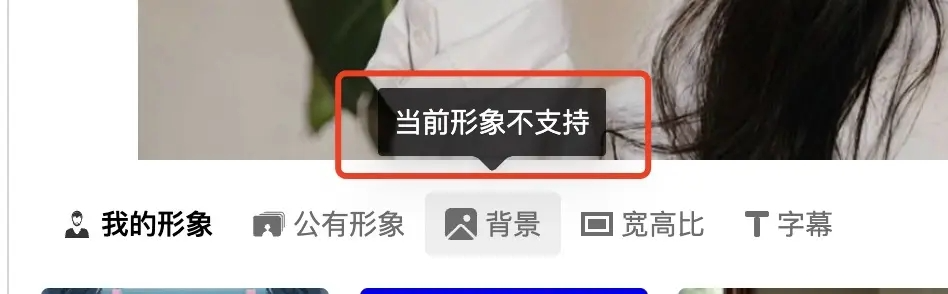
首先,并不是所有的形象都支持更换背景。如果您把鼠标放到“背景”上,提示”当前形象不支持”,则您需选择其他形象。对于您自己创建的形象,你需要在创建形象时同时选择背景色,才能获得支持更换“背景”的形象。使用个性化克隆形象生成视频
您可以使用线下真实人物拍摄的一小段视频,生成个性化克隆形象的基础视频模型,后续可基于此基础视频模型生成短视频,短视频中人物的形象、声音、唇形、动作、服装道具则与拍摄那小段视频一致。我们称这一小段原始的视频和音频为基础视频。同一个人,可能因为使用场景发生改变而拍摄的动作需要变化(比如坐姿改为站姿)、表情需要变化(微笑改为严肃)、衣着需要变化(正装改为休闲等)等等,拍摄处的不同的小视频,被定义为不同的基础视频。基础视频的拍摄有特定要求,具体要求请见Q&A2。第一次训练默认为瞬时模式形象克隆,一分钟完成数字人形象创建(免费不消耗钻石)。如对瞬时模式训练效果不满意,可点击“继续训练”消耗一个钻石等待两小时得到超逼真数字人模型!具体操作步骤如下:拍摄基础视频后,选择“视频生成形象”模块按照页面信息“视频生成形象操作流程”和“原始素材要求”的内容去上传对应视频和操作。使用自有声音生成克隆声音
可以利用线下真实人物的一小段音频,通过系统训练,生成音频模型。音频的录制有特定要求,具体要求请见Q&A4。选择“声音克隆”模块,按照“如何使用”的要求,上传音频后点击“开始训练”即可,生成的音频模型会在页面右部显示。(1)您上传的音频没有背景噪音,没有背景音乐
(2)您上传的音频是高清音质wav格式。上传音频的质量比长度更重要。高质量的30秒音频就足够做出高质量的克隆声音
3)您上传的音频需要包含带语气的完整的一段话,避免“123123”这种重复没有意义的话术。如果以上要求您都满足,或者您需要克隆的原始音频无法修改,则您在合成时候需要输入少于100个字的文案,把长文案拆成多段合成。文字个数少于100个的时候,语音合成效果明显优于长文本
换脸功能
可以通过换脸功能,将基础视频中的形象与上传照片中的形象进行脸型、五官等方面的替换。上传需要进行换脸的视频和替换人脸图片,操作流程和要求可点击信息查看,点击效果预览,预览展示图满意的话,点击开始换脸,进行处理。视频去字幕
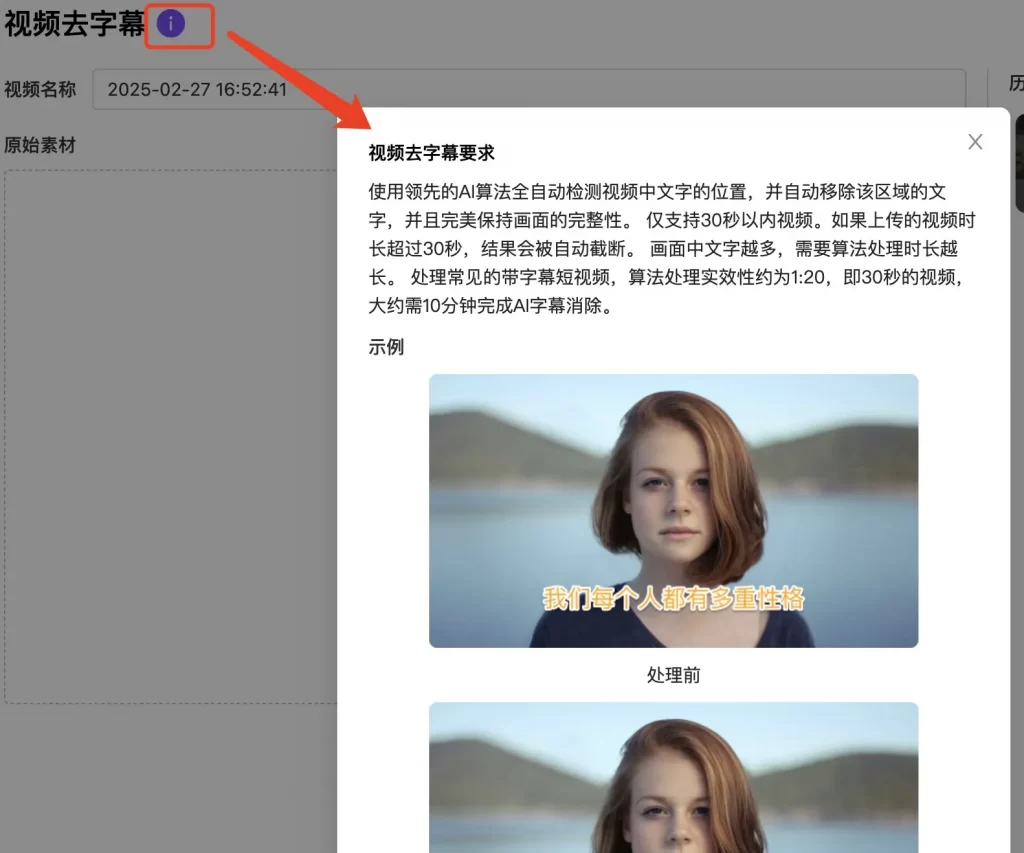
可以通过视频去字幕功能,将带有字幕的视频进行上传。算法会自动识别移除该区域的文字,并且完美保持画面的完整性。处理完成后您将获得一个没有任何文字痕迹的视频!时长要求:30s以内 (如果上传的视频时长超过30秒,结果会被自动截断)点击问号logo查看上传符合 “视频去字幕要求” 的视频,随后点击“AI去字幕”Q&A1:如何登录页面及账号?
通过下单时留下的邮箱/手机号进行登录,如果未注册,可先自行注册。Q&A2:如何拍摄一段合格的“基础视频”?
1.1 过程建议
环境建议:(1) 灯光建议:影棚人像灯光组,至少需要有前景光源,和背光(轮廓)光源,人物离绿幕尽量远(2米及以上)便于达到比较好的绿幕抠图效果,注意避免衣物或道具反射绿光;(2)声音建议:环境背景噪音需小于45db,无回声,无混响,建议录制前做好检测;设备建议:(1)专业录像与录音设备:录像设备建议索尼A7S3或A7M4,录音设备建议小蜜蜂,40mm或者50mm大光圈镜头(建议50mm F1.8 定焦镜头),光圈F2.8~F4,快门不高于1/100,ISO不高于800(具体参数需根据实际灯光环境调试);(2)其他设备(电脑、视频采集卡、提词器等):根据实际情况而定,能满足需求即可;录制参数:建议2k/30帧(如需高清可设定更高参数),非HDR格式;拍摄建议:(1)视频中要有声音,要保持音画同步;(2)动作建议:相机需正对面部。讲话时,眼睛可以看提词器,提词器需要和相机处于同一方位,声音洪亮清晰,说错跳过下一句,动作幅度不超过相机采集框,不遮挡脸部。可以根据讲话习惯做一些轻微动作(例如:手势比划、头部晃动之类,但不要用有意义的动作——赞美/否定性动作等),需使用通用动作,动作幅度不宜过大,且动作频率不能过高,不能遮挡面部。嘴唇开合可以适度明显一些,可以比日常生活中稍夸张一些。讲话的内容可以由被拍摄者准备,也可根据被拍摄者的情况,简化素材为背诵熟悉的诗词、数字、字母等。(3)抠图需求:如后期需更换背景,以上视频均需采集1-2秒空镜头;特别说明:(1)视频中出现的动作会在最终生成视频时按照拍摄时的动作顺序播放;(2)需避开绿色或蓝色服装(避免抠图误识别)等,不支持AI更换服饰;(3)可佩戴框架眼镜。1.2 结果要求
时长要求:30秒-5分钟;音画同步要求:视频中需要讲话,且必须音画同步,音频和嘴唇运动必须同步。其他要求:视频中只能包含一张脸;不允许环境噪音或其他声音(除了您的讲话);保持适度的语速(语速过慢可能会降低嘴唇同步精度;语速过快可能会导致嘴唇同步抖动)Q&A3:如何解决“上传文件类型不确定”的问题?
当遇到显示“上传文件类型不确定”时,可以使用“剪映”刷一下格式(如原文件是MP4模式,但因为是相机里导出的原始视频等原因,系统无法确定文件类型,用“剪映”刷一下格式即可,格式可同样还是MP4格式)。先查看一下原始视频的参数,右键点击视频的属性-详细信息,主要关注”帧宽/高度”、”总比特率”和“帧速率”,在剪映中选/填的参数要符合原始视频的参数。例如,下图为原始视频的参数。打开剪映,“导入”原始视频后,在“导出”时,选择如下参数(注意是选择CBR而不是VBR),导出后的视频文件即可被视频合成平台使用。Q&A4:如何录制一段合格的“基础音频”?
1.1 过程建议
素材时长:15秒 – 60秒;环境要求:环境背景噪音需小于45db,无回声,无混响,录制前需做好检测;设备要求:指向性电容麦克(例如心形指向);录制要求:使用麦克风录制符合客户使用场景语气语调的声音(该语气即交付后合成音频的语气),不要把设备放在嘴边,避免有喷麦的声音,说错可跳过继续下一句。注意关闭混响,无需对原始音频文件进行任何后期调整;录制参数:48k,16bit,单声道,标准化后增益应该在0.4以上;推荐软件:Adobe Audition;1.2 结果要求
语音文件支持mp3和wav格式,音频数量最多1条,时长为1-5分钟,优质模式时长需要5分钟及以上。单人清晰人声,无背景噪音,房间混响,音量音调均匀,没有极长的沉默间隙。Q&A 5:克隆声音有杂音或漏字怎么办?
目前克隆声音算法还处于持续迭代中。如果您克隆的声音有杂音或者漏字请首先检查(1)您上传的音频没有背景噪音,没有背景音乐
(2)您上传的音频是高清音质wav格式。上传音频的质量比长度更重要。高质量的30秒音频就足够做出高质量的克隆声音
(3)您上传的音频需要包含带语气的完整的一段话,避免“123123”这种重复没有意义的话术。如果以上要求您都满足,或者您需要克隆的原始音频无法修改,则您在合成时候需要输入少于100个字的文案,把长文案拆成多段合成。文字个数少于100个的时候,语音合成效果明显优于长文本
阅读全文













请先 登录后发表评论 ~